XPath,全称 XML Path Language,即 XML 路径语言。它使用路径表达式来选取 XML 文档中的节点或节点集。
Python 使用 XPath 要先安装 lxml 库
XPath的简单调用方法:
1 | from lxml import etree |
节点、元素、标签的关系
将 HTML 文档视作树结构,每个 HTML 元素都是元素节点。节点还包括文本节点、属性节点等。
HTML 源码中被尖括号(<和>)包起来的是标签,比如<head>、<body>。大多数标签都成对使用 <p></p>,成对标签和它们之间的一切形成一个元素,标签名就是元素名。
节点关系
- a 节点包括 b 节点,则 a 就是 b 的父节点,b 就是 a 的子节点。
- 拥有相同父节点的是同胞节点
- 某节点的父,父的父,等等,是其先辈节点
- 某节点的子,子的子,等等,是其后代节点
示例:
1 | <bookstore> |
<bookstore>是<book>的父节点
<title>、<author>、<year>、<price>都是<book>的子节点
<title>、<author>、<year>、<price>互相之间是同胞节点
<bookstore> 、<book>是<title>的先辈节点
<book> 、 <title>是<bookstore>的后代节点
语法
常用路径表达式
/从当前节点选取直接子节点,或对当前节点进行操作
//从当前节点选取后代节点
..选取当前节点的父节点
@选取属性
示例:
/bookstore选取根元素 bookstore
bookstore/book选取 bookstore 元素的直接子元素中的 book 元素
//book选取文档中的所有 book 元素
bookstore//book选取 bookstore 元素的所有后代 book 元素
//@lang选取文档中包含 lang 属性的所有元素
谓语
示例:
/bookstore/book[1]选取 bookstore 子元素中的第一个 book 元素
/bookstore/book[last()]选取 bookstore 子元素中的最后一个 book 元素
/bookstore/book[last()-1]选取 bookstore 子元素中的倒数第二个 book 元素
//title[@lang]选取所有拥有 lang 的属性的 title 元素
//title[@lang='eng']选取所有拥有 lang 属性且值为 eng 的 title 元素
通配符
示例:
/bookstore/*选取 bookstore 元素的所有子元素
//*选取文档中的所有元素
//title[@*]选取所有带有属性的 title 元素
运算符
|选取若干路径
示例:
//title | //price选取文档中的所有 title 和 price 元素
属性
attribute::lang选取当前节点的 lang 属性
不含某属性
//p[not(@class)]选取不含 class 属性的所有 p 节点
//p[not(@class or @id)]选取不含 class 属性和 id 属性的所有 p 节点
文本
/text()获取节点中的文本
示例
1 | # python3 |
获取网页某节点 xpath 的方法:
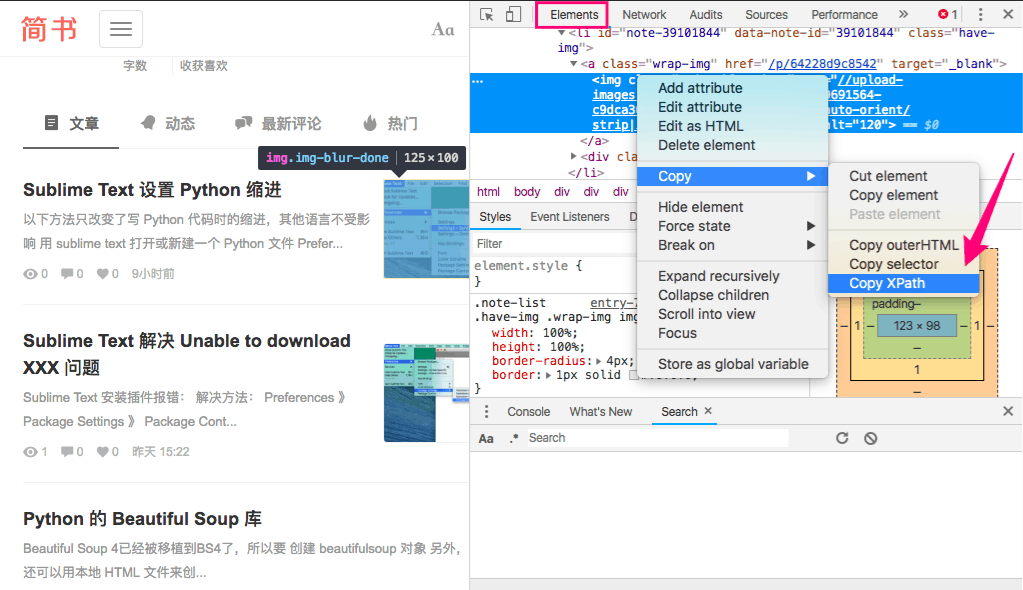
Chrome浏览器,打开开发者工具(Windows 快捷键 F12,Mac 快捷键 command+option+I)
在 elements 中找到想要获取 XPath 的标签,
单击右键,选择 Copy 》 Copy XPath,XPath路径就复制到剪切板了
或者:
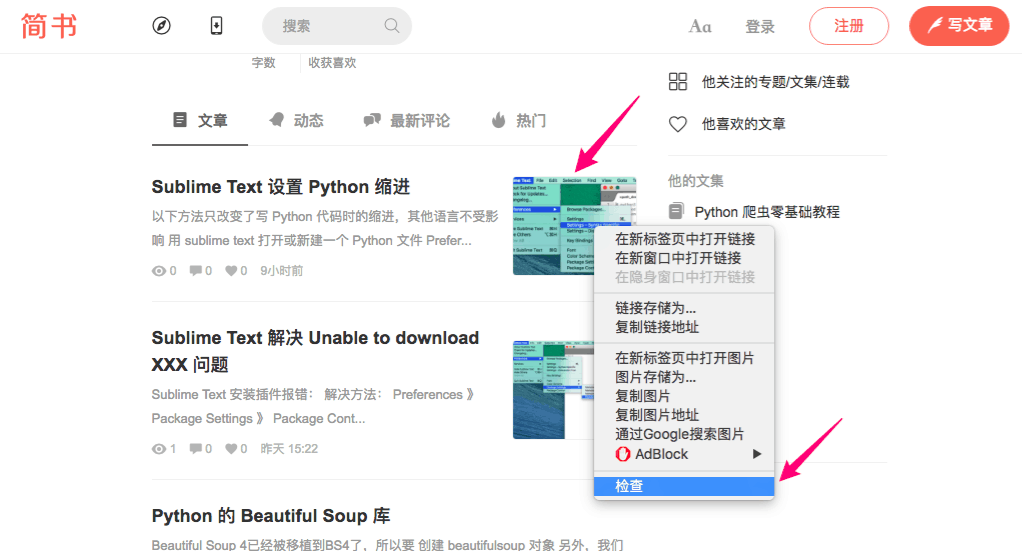
把鼠标放在目标数据上,点击右键,点击”检查”
在弹出的 Elements 窗口,就已经定位到了该元素的位置
然后右键,选择 Copy 》 Copy XPath,XPath路径就复制到剪切板了
报错:
1 | lxml.etree.XPathEvalError: Invalid predicate |
通常是使用 xpath 的语法里方括号没写全,例如:
1 | [@width="220" |
解决方法:补全符号
1 | [@width="220"] |
鸣谢:
XPath 语法 - w3school
使用XPath - 静觅
2018-12-29